Multi-Source Crawling
Scrape 55+ job boards, ATS platforms, and custom URLs from one control panel — zero duplicates.
Built for Hireed AI: multi-source scraping, global coverage, duplicate-safe storage, and dashboard workflow for tracking applications.
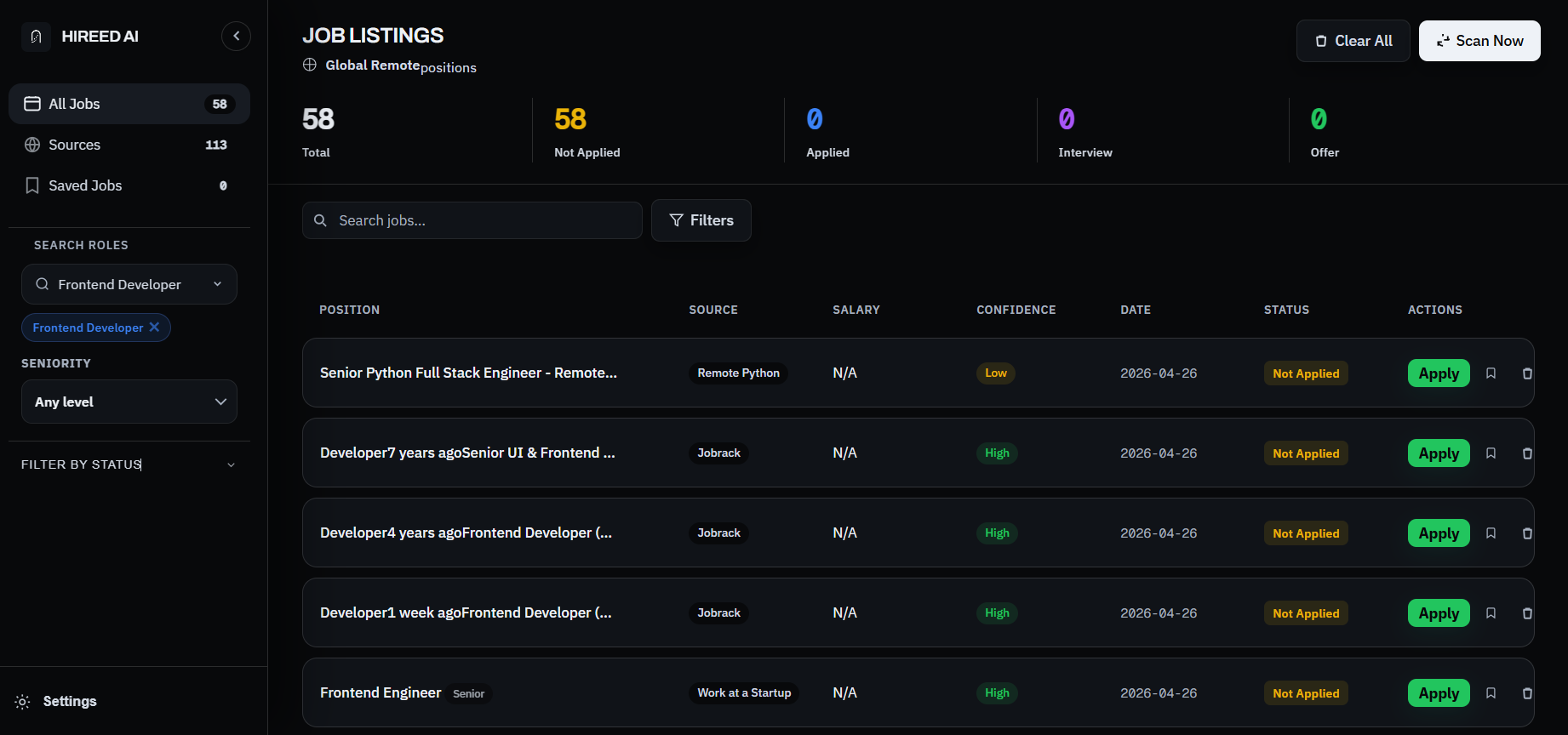
A production-grade engine that crawls, matches, and organizes — so your pipeline stays clean from source to decision.
Scrape 55+ job boards, ATS platforms, and custom URLs from one control panel — zero duplicates.
Match every listing against role taxonomy, seniority, and skill-intent to eliminate false positives automatically.
Track application status, confidence levels, and source performance in a clean daily workflow view.
Gemini validates scraped titles in real-time — keeping only jobs that genuinely match your target roles.
Multi-threaded engine processes sources in parallel — a full scan across 55 sites finishes in minutes, not hours.
All data stays in your local SQLite database. No cloud dependency, no third-party analytics, no tracking.
Add any board to your pipeline. Hireed AI auto-detects ATS type and selects the optimal scraping strategy.
From role-specific query orchestration to structured review, Hireed AI gives you everything needed to scale hiring discovery with confidence.
"We replaced manual sourcing loops with a measurable pipeline. The relevance quality is dramatically better."
"The dashboard gives us immediate control. We spend less time cleaning data and more time engaging candidates."
"Hireed AI made our sourcing process repeatable across roles. It's now part of our core weekly operations."
Start free and scale as your sourcing needs grow.
The pipeline combines rule-based matching with AI-powered title relevance validation. Each scraped job is scored against your target role taxonomy, seniority preferences, and skill-intent signals to prioritize the highest-fit opportunities.
Yes. Teams can add any URL — including custom career pages, ATS platforms, and niche boards. Hireed AI auto-detects the site type and selects the optimal scraping strategy automatically.
Absolutely. The role taxonomy supports any combination of categories — Technology, Design, Marketing, Sales & Product, and Data Science — with saved preferences that persist across hiring cycles.
All data is stored locally in a SQLite database file on your machine. There is no cloud dependency, no third-party tracking, and no external data sharing. Your pipeline data stays entirely private.